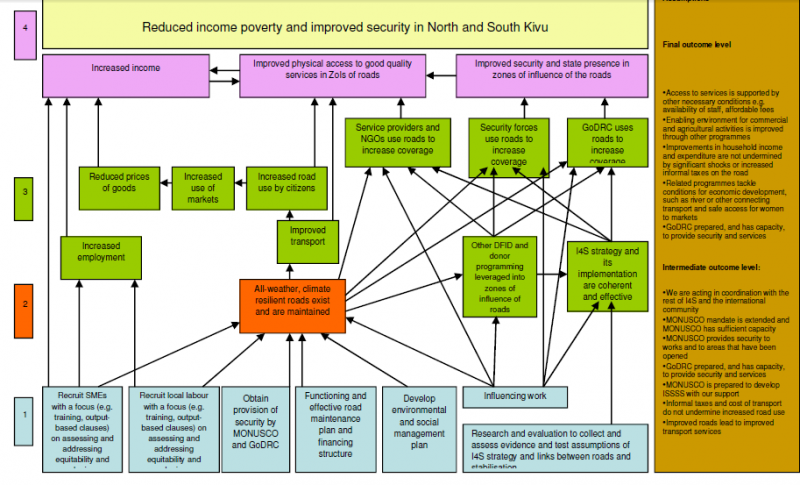
.
I have just found out about the existence of a field of study called "temporal networks" Here are two papers I came across
The x-axis represents intervals of time The y-axis represents six different actors. The curved lines represent particular connections between particular actors at particular moments of time. For example, email messages or phone calls.
In Figure 2 below, we can see a more familiar type of network structure. This is the same network as that shown in Figure 1. The difference is that it is an aggregation of all the interactions over the 24 time periods shown in Figure 1. The numbers in red refer to the number of times that each communication link was active in this whole period.
This diagram has both some strengths and weaknesses. Unlike Figure 1 it shows us the overall structure of interactions. On the other hand, it is obscuring the possible significance of variations in the sequence within which these interactions take place over time. In a social setting involving people talking to each other, the sequencing of when different people talk to each other could make a big difference to the final state of the relationships between the people in the network.
How might the Figure 1 way of representing temporal networks be useful?
The first would be as a means of translating narrative accounts of events into network models of those events. Imagine that the 24 time periods are a duration of time covered by events described in a novel. And events in periods 1 to 5 are described in one particular chapter of the novel. In a chapter, the story is all about the interactions between actors 2, 3 and 4. In subsequent chapters, their interactions with other actors are described.
Now, instead of a novel, imagine a narrative describing the expected implementation and effects of a particular development programme. Different stakeholders will be involved at different stages. Their relationships could be "transcribed" into a temporal network, and also then into a static network diagram (as in Figure 2) which would describe the overall set of relationships for the whole programme period.
The second possible use would be to adapt the structure of a temporal network model to convert it into a temporal causal network model. Such as shown in Figure 4 below. The basic structure would remain the same, with actors list row by row and time listed column by column. The differences would be that:
One possible problem is whether measurable indicators could be developed for each activity that is shown. Another is how longer-term outcomes, happening over a period of time, might be captured. Perhaps the activities associated with their measurement would be what would be shown in a Figure 4 type model.
Postscript: The temporal dimension of network structures is addressed in dynamic network models, such as those captured in Fuzzy Cognitive Networks. With each iteration of a dynamic network model, the states of the nodes/events/actors in the network are updated according to the nature of the links they have with others in the network. This can lead to quite complex patterns of change in the network over time. But one of the assumptions built into such models is that all relationships are re-enacted in each iteration. This is clearly not the case in our social life. Some relationships are updated daily, others much less frequently. The kind of structure shown in Figure 1 above seems more appropriate view. But can these be used for simulation purposes, where all nodes would have values that are influenced by their relationships with each other?
I have just found out about the existence of a field of study called "temporal networks" Here are two papers I came across
Linhares, C. D. G., Ponciano, J. R., Paiva, J. G. S., Travençolo, B. A. N., & Rocha, L. E. C. (2019). Visualisation of Structure and Processes on Temporal Networks. In P. Holme & J. Saramäki (Eds.), Temporal Network Theory (pp. 83–105). Springer International Publishing. https://doi.org/10.1007/978-3-030-23495-9_5
Li, A., Cornelius, S. P., Liu, Y.-Y., Wang, L., & Barabási, A.-L. (2017). The fundamental advantages of temporal networks. Science, 358(6366), 1042–1046. https://doi.org/10.1126/science.aai7488
Here is an example of a temporal network:
 |
| Figure 1 |
The x-axis represents intervals of time The y-axis represents six different actors. The curved lines represent particular connections between particular actors at particular moments of time. For example, email messages or phone calls.
In Figure 2 below, we can see a more familiar type of network structure. This is the same network as that shown in Figure 1. The difference is that it is an aggregation of all the interactions over the 24 time periods shown in Figure 1. The numbers in red refer to the number of times that each communication link was active in this whole period.
This diagram has both some strengths and weaknesses. Unlike Figure 1 it shows us the overall structure of interactions. On the other hand, it is obscuring the possible significance of variations in the sequence within which these interactions take place over time. In a social setting involving people talking to each other, the sequencing of when different people talk to each other could make a big difference to the final state of the relationships between the people in the network.
 |
| Figure 2 |
The first would be as a means of translating narrative accounts of events into network models of those events. Imagine that the 24 time periods are a duration of time covered by events described in a novel. And events in periods 1 to 5 are described in one particular chapter of the novel. In a chapter, the story is all about the interactions between actors 2, 3 and 4. In subsequent chapters, their interactions with other actors are described.
 |
| Figure 3 |
The second possible use would be to adapt the structure of a temporal network model to convert it into a temporal causal network model. Such as shown in Figure 4 below. The basic structure would remain the same, with actors list row by row and time listed column by column. The differences would be that:
- The nodes in the network could be heterogeneous, reflecting different kinds of activities or events, undertaken/involved in by each actor. Not homogenous as in Figure 1 example above.
- The connections between activities/events would be causal, in one direction or in both directions. The latter signifying a two-way exchange of some kind. In Figure 1 causality may be possible and even implied, but it can't simply be assumed.
- There could also be causal links between activities within the same row, meaning an actor's particular at T1 influenced another of their activities in T3, for example. This possibility is not available in Figure 1 type model
- Some spacer" rows and columns are useful to give the node descriptions more and to make the connections between them more visible
Figure 4 is a stylised example. By this I mean I have not detailed the specifics of each event or characterised the nature of the connections between them. In a real-life example this would be necessary. Space limitations on the chart would necessitate very brief titles + reference numbers or hypertext links.
 |
| Figure 4: Stylised example |
While this temporal causal network looks something a Gantt chart it is different and better.
How does a temporal causal network compare to more conventional representations of Theories of Change? Results chains versions of a Theory of Change do make use of a y-axis to represent time but are often much less clear about the actors involved in the various events that happen over time. Too often these describe what might be called a sequence of disembodied events i.e. abstract descriptions of key events. On the other hand, more network like Theories of Change can be better at identifying the actors involved in the relationships between them. But it is very difficult to also capture the time dimension in a static network diagram. Associated with this problem is the difficulty of then constructing any form of text narrative about the events described in the network.- Each row is an about a specific actor, whereas in a Gantt chart each row is about a specific activity
- Links between activities signal a form of causal influence , whereas in a Gantt chart they signal precedence which may or may not have causal implications
- Time periods can be more flexibly and abstractly defined, so long as they follow a temporal sequence. Whereas in a Gannt chart these are more likely to be defined in specific units like days, weeks or months, or specific calendar dates
One possible problem is whether measurable indicators could be developed for each activity that is shown. Another is how longer-term outcomes, happening over a period of time, might be captured. Perhaps the activities associated with their measurement would be what would be shown in a Figure 4 type model.
Postscript: The temporal dimension of network structures is addressed in dynamic network models, such as those captured in Fuzzy Cognitive Networks. With each iteration of a dynamic network model, the states of the nodes/events/actors in the network are updated according to the nature of the links they have with others in the network. This can lead to quite complex patterns of change in the network over time. But one of the assumptions built into such models is that all relationships are re-enacted in each iteration. This is clearly not the case in our social life. Some relationships are updated daily, others much less frequently. The kind of structure shown in Figure 1 above seems more appropriate view. But can these be used for simulation purposes, where all nodes would have values that are influenced by their relationships with each other?